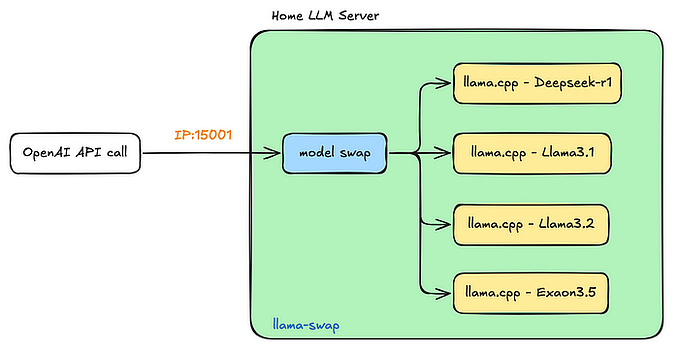
Build Your Own Offline AI Chatbot: Running DeepSeek Locally with Ollama
3 min readFeb 6, 2025
This guide will walk you through creating a local chatbot using DeepSeek and Ollama, with a Streamlit interface.
Setting Up Ollama
- Download Ollama from ollama.com/download
- Installation:
- Windows: Run the downloaded installer
- macOS: Download and move to Applications folder
- Linux: Run
curl -fsSL https://ollama.com/install.sh | sh
Installing DeepSeek Model
- Search for available models at ollama.com/search
- Install and run DeepSeek model:
- For macOS/Linux (Terminal):
ollama run deepseek-r1:1.5b- For Windows (Command Prompt):
ollama run deepseek-r1:1.5b3. Create models.txt in your project directory:
deepseek-r1:1.5bProject Setup
- Create a new directory and set up virtual environment:
mkdir deepseek-chat
cd deepseek-chat
python -m venv venv
source venv/bin/activate # On Windows: venv\Scripts\activate2. Create requirements.txt:
streamlit
requests
typing3. Install dependencies:
pip install -r requirements.txtCreating the Chatbot
Create app.py with the following code:
import streamlit as st
import requests
import json
from typing import Iterator
# Hide Streamlit menu and footer
hide_streamlit_style = """
<style>
#MainMenu {visibility: hidden;}
footer {visibility: hidden;}
header {visibility: hidden;}
</style>
"""
OLLAMA_API_BASE = "http://localhost:11434"
def load_models() -> list[str]:
try:
with open('models.txt', 'r') as f:
return [line.strip() for line in f if line.strip()]
except FileNotFoundError:
return ["deepseek-r1:7b"]
def generate_stream(prompt: str, model: str) -> Iterator[str]:
response = requests.post(
f"{OLLAMA_API_BASE}/api/generate",
json={
"model": model,
"prompt": prompt,
"stream": True
},
stream=True
)
for line in response.iter_lines():
if line:
json_response = json.loads(line)
if 'response' in json_response:
yield json_response['response']
if json_response.get('done', False):
break
def extract_thinking_and_response(text: str) -> tuple[str, str]:
think_start = text.find("<think>")
think_end = text.find("</think>")
if think_start != -1 and think_end != -1:
thinking = text[think_start + 7:think_end].strip()
response = text[think_end + 8:].strip()
return thinking, response
return "", text
def main():
st.set_page_config(
page_title="DeepSeek Chat",
page_icon="🤖",
layout="wide"
)
st.markdown(hide_streamlit_style, unsafe_allow_html=True)
with st.sidebar:
st.title("Settings")
available_models = load_models()
selected_model = st.selectbox(
"Choose a model",
available_models,
index=0
)
st.title("💭 DeepSeek Chat")
if "messages" not in st.session_state:
st.session_state.messages = []
for message in st.session_state.messages:
with st.chat_message(message["role"]):
if message["role"] == "assistant" and "thinking" in message and message["thinking"]:
with st.expander("Show reasoning", expanded=False):
st.markdown(message["thinking"])
st.markdown(message["content"])
if prompt := st.chat_input("What would you like to ask?"):
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.markdown(prompt)
with st.chat_message("assistant"):
message_placeholder = st.empty()
thinking_placeholder = st.empty()
message_placeholder.markdown("🤔 Thinking...")
full_response = ""
last_thinking = ""
try:
with thinking_placeholder.container():
thinking_expander = st.expander("Show reasoning", expanded=False)
for response_chunk in generate_stream(prompt, selected_model):
full_response += response_chunk
thinking, response = extract_thinking_and_response(full_response)
if thinking and thinking != last_thinking:
with thinking_expander:
st.markdown(thinking)
last_thinking = thinking
message_placeholder.markdown(response + "▌")
thinking, response = extract_thinking_and_response(full_response)
message_placeholder.markdown(response)
st.session_state.messages.append({
"role": "assistant",
"content": response,
"thinking": thinking
})
except requests.exceptions.RequestException as e:
st.error("Error: Could not connect to Ollama server")
st.info("Make sure Ollama is running and accessible at localhost:11434")
if __name__ == "__main__":
main()Running the Chatbot
- Start Ollama service
- Run the Streamlit app:
streamlit run app.pyThe chatbot will be available at http://localhost:8501. It provides a clean interface with model selection in the sidebar and a chat interface in the main window. The bot supports streaming responses and can show its reasoning process in expandable sections.